Initializing PPM
The method of context building from the previous part is relatively simple. All these branches of contexts can be understood quite intuitively, and it is not complicated to show them in an image. That’s why I decided to show it first to familiarize you with PPM. But during the encoding of each symbol, we should start searching from CM(0) and search for the symbol in each of the contexts along the way. In this part, we will look at another way of how we can handle the building of the PPM context tree. It is less intuitivele, so if you struggle to understand why it works, that’s okay.
I have two pieces of good news right ahead. First, the relationship between the image count and the lines of code in this part will be greater. In fact, we will rewrite only three functions. The second good news is that we can throw away some code that we spent time on in the previous part right at the beginning. Specifically, we no longer need the following functions and structs:
1
2
3
4
5
6
7
struct symbol_search_result;
struct find_context_result;
b32 encodeSymbol(ArithEncoder& Encoder, context* Context, u32 Symbol);
b32 decodeSymbol(ArithDecoder& Decoder, context* Context, u32* ResultSymbol);
symbol_search_result findSymbolIndex(context* Context, u32 Symbol);
void findContext(find_context_result& Result);
Now our PPMByte looks like this:
1
2
3
4
5
6
7
8
9
10
11
12
class PPMByte
{
context_data_excl* Exclusion;
context* MaxContext;
context* MinContext;
context_data** ContextStack;
context_data* LastEncSym;
u16 OrderCount;
u16 LastMaskedCount;
...
}
From the previous part, we are only left with Exclusion and OrderCount. The purpose of the remaining new variables will be easier to see from example, so I will not go into detail about them for now.
Since we completely changed the method of building contexts, the initialization will be done differently.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
void initModel()
{
Exclusion = SubAlloc.alloc<context_data_excl>(1);
clearExclusion();
ContextStack = SubAlloc.alloc<context_data*>(OrderCount);
context* Order0 = SubAlloc.alloc<context>(1);
Assert(Order0);
ZeroStruct(*Order0);
MaxContext = Order0;
Order0->TotalFreq = 257;
Order0->SymbolCount = 256;
Order0->EscapeFreq = 1;
Order0->Data = SubAlloc.alloc<context_data>(256);
for (u32 i = 0; i < Order0->SymbolCount; ++i)
{
Order0->Data[i].Freq = 1;
Order0->Data[i].Symbol = i;
Order0->Data[i].Next = nullptr;
}
for (u32 OrderIndex = 1;; OrderIndex++)
{
MaxContext = allocContext(MaxContext->Data, MaxContext);
if (OrderIndex == OrderCount) break;
MaxContext->SymbolCount = 1;
MaxContext->Data[0].Freq = 1;
MaxContext->Data[0].Symbol = 0;
}
MinContext = MaxContext->Prev;
}
Unlike the previous approach, we no longer have CM(-1). Instead, we use СM(0) as our first context, which, like the CM(-1), should initialize all symbols of our alphabet since encoding and decoding now start from it. As before, we allocate memory for the ContextStack in advance, but this time it’s an array of context_data* rather than a find_context_result. At the bottom, we initialize MinContext and MaxContext, on which the work of the new context construction method is based, with an initial pointer on the newly created context. After all this manipulation, our context tree will look like this.
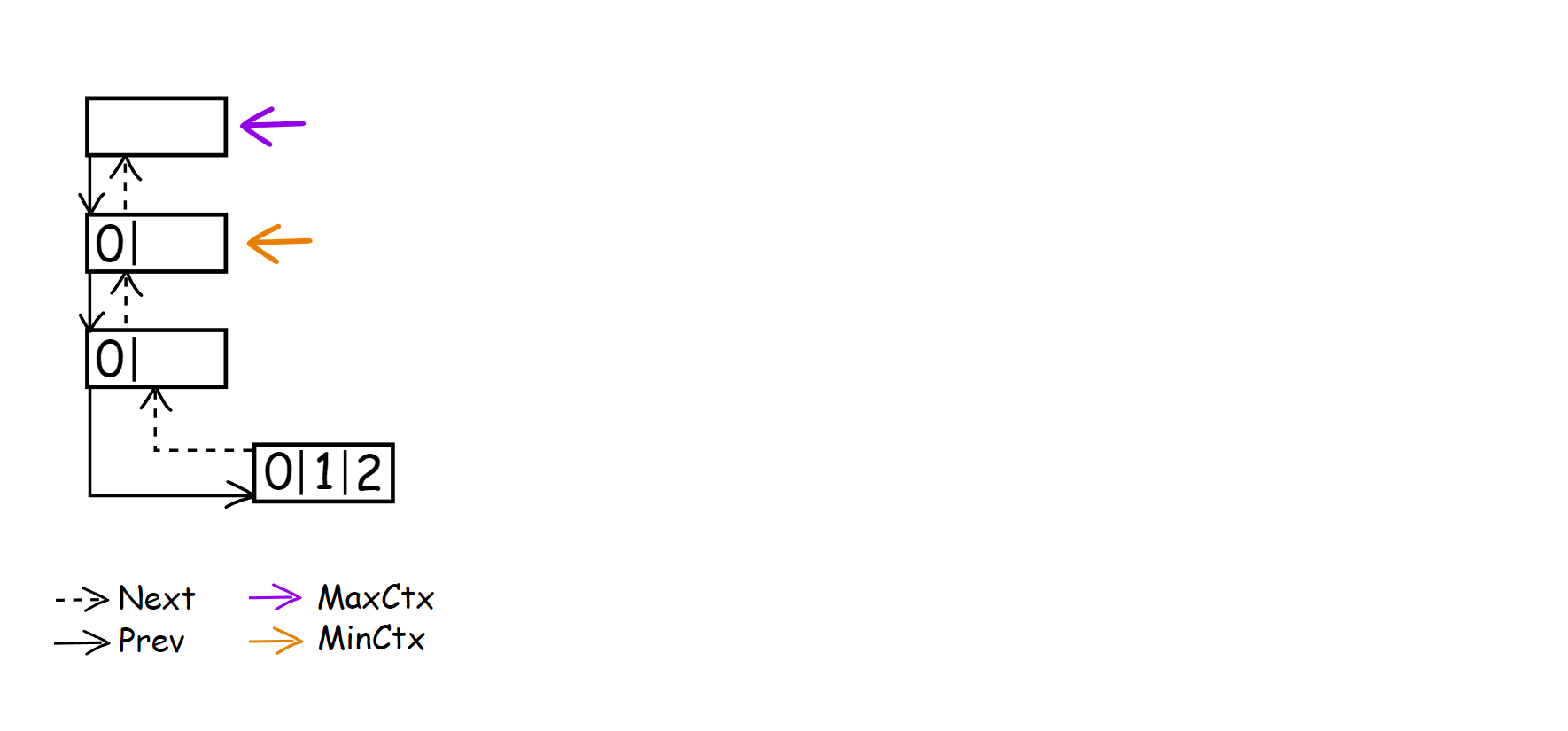
To demonstrate the process of building context, I have chosen the sequence 121212212. The alphabet will consist of the symbol {0, 1, 2}, and the depth will be Order-3. If larger alphabet was taken with a more complex sequence of symbols, the final figure would become more richer in terms of the possible tree structure that can arise, but it would quickly become cumbersome. That’s why I chose to do it like this. It will still illustrate the main idea, I believe.
Context search loop
Encoding
Like in the previous part, let’s start with how we are doing context searching.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
void encode(ArithEncoder& Encoder, u32 Symbol)
{
prob Prob = {};
b32 Success = getEncodeProb(Prob, Symbol);
Encoder.encode(Prob);
while (!Success)
{
do
{
MinContext = MinContext->Prev;
} while (MinContext && (MinContext->SymbolCount == LastMaskedCount));
if (!MinContext) break;
Success = getEncodeProb(Prob, Symbol);
Encoder.encode(Prob);
}
if (MinContext == MaxContext)
{
MinContext = MaxContext = LastEncSym->Next;
}
else if (MinContext)
{
update();
}
clearExclusion();
}
MinContext points to the current context we are using for encoding, allowing us to immediately attempt to encode a symbol. We no longer need to pass a pointer to the context in getEncodeProb() and getSymbolFromFreq() since it is already stored in MinContext. If the first attempt to encode a symbol fails, we start descending through the chain of child context to search suitable context to encode the symbol. You can imagine it as each branch of the context representing a sequence of child contexts by default now. The condition of the first while loop is clear I think: if encoding was successful then we break out of the loop. In the loop of a context search, we check if the value of Order0->Prev has been assigned to MinContext and ignore a context if it has the same number of symbols as the previous MinContext. This is because it indicates that both contexts have the same context_data values within them. The value of LastMaskedCount is set at ESC encoding/decoding in getEncodeProb() and getSymbolFromFreq().
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
b32 getEncodeProb(prob& Prob, u32 Symbol)
{
...// calculate CumFreqLo
if (SymbolIndex < MinContext->SymbolCount)
{
context_data* MatchSymbol = MinContext->Data + SymbolIndex;
LastEncSym = MatchSymbol;
...// calculate Prob.hi, update Symbol freq and TotalCount
}
else
{
Prob.hi = Prob.scale = Prob.lo + MinContext->EscapeFreq;
LastMaskedCount = MinContext->SymbolCount;
updateExclusionData(MinContext);
}
return Result;
}
I moved updateExclusionData() into the functions that calculate the Prob struct because of the way we exit from the context searching loop now.
The condition if (MinContext == MaxContext) means that we’re in the state when we don’t need to add context branches or add new symbols to existing contexts. That’s why in this case, we can skip the update() and simply move to the next parent context. Why it is the case you will see in a futher example.
Decoding
The decode() function is almost no different.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
u32 decode(ArithDecoder& Decoder)
{
decode_symbol_result DecSym;
DecSym = getSymbolFromFreq(Decoder);
Decoder.updateDecodeRange(DecSym.Prob);
while (DecSym.Symbol == EscapeSymbol)
{
do
{
MinContext = MinContext->Prev;
} while (MinContext && (MinContext->SymbolCount == LastMaskedCount));
if (!MinContext) break;
DecSym = getSymbolFromFreq(Decoder);
Decoder.updateDecodeRange(DecSym.Prob);
}
if (MinContext == MaxContext)
{
MinContext = MaxContext = LastEncSym->Next;
}
else if (MinContext)
{
update();
}
clearExclusion();
return DecSym.Symbol;
}
We changed the calls to getEncodeProb() and Encoder.encode() to getSymbolFromFreq() and Decoder.updateDecodeRange(). Also, we descend here to the child context until we keep getting the ESC symbol.
New update scheme
The hardest part begins in update().The idea is to construct new parent contexts for all contexts between MinContext and MaxContext and properly assign to each one the appropriate child context. If we didn’t find the symbol in the chain of child contexts, we add it to all contexts that are between MinContext and MaxContext. For example, if we encoded a symbol ‘q’ in CM(0) and before this our CM(3) from which we descend was <abc>, then we initialize the symbol ‘q’ in CM(3) <abc>, CM(2) <bc>, CM(1) <c>.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
void update()
{
context_data** StackPtr = ContextStack;
context* ContextAt = MaxContext;
u16 InitFreq = 1;
if (ContextAt->SymbolCount == 0)
{
do
{
context_data* First = ContextAt->Data;
First->Symbol = LastEncSym->Symbol;
First->Freq = InitFreq;
ContextAt->SymbolCount = 1;
ContextAt = ContextAt->Prev;
*StackPtr++ = First;
} while (ContextAt->SymbolCount == 0);
}
... // alloc symbol, alloc and link context
}
We start by adding a symbol to the contexts that don’t have any symbols while, at the same time, stacking them to the ContextStack. Since we know for sure that LastEncSym is set at the last encoded symbol (because otherwise MinContext would be equal to nullptr and we couldn’t start the execution of update()), we use it to initialize the Symbol value for all context_data.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
context_data* allocSymbol(context* Context)
{
context_data* Result = nullptr;
u32 PreallocSymbol = getContextDataPreallocCount(Context);
Context->Data =
SubAlloc.realloc(Context->Data, ++Context->SymbolCount, PreallocSymbol);
if (Context->Data)
{
Result = Context->Data + (Context->SymbolCount - 1);
ZeroStruct(*Result);
}
return Result;
}
void update()
{
...// init context that have SymbolCount == 0
context_data* NewSym;
for (; ContextAt != MinContext; ContextAt = ContextAt->Prev, *StackPtr++ = NewSym)
{
NewSym = allocSymbol(ContextAt);
if (!NewSym)
{
ContextAt = nullptr;
break;
}
ContextAt->EscapeFreq += 1;
ContextAt->TotalFreq += 1;
NewSym->Freq = InitFreq;
NewSym->Symbol = LastEncSym->Symbol;
}
...// alloc and link context
}
allocSymbol() is the previous addSymbol(), but now we receive a pointer to the new context_data* and perform initialization inside update() itself.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
context* allocContext(context_data* From, context* Prev)
{
context* New = nullptr;
New = SubAlloc.alloc<context>(1);
if (New)
{
New->Data = SubAlloc.alloc<context_data>(2);
if (New->Data)
{
From->Next = New;
New->Prev = Prev;
New->TotalFreq = 1;
New->EscapeFreq = 1;
New->SymbolCount = 0;
}
else
{
New = nullptr;
}
}
return New;
}
void update()
{
.../* init context with SymbolCount == 0, alloc symbol for other context,
add all processed context to ContextStack */
if (ContextAt)
{
if (LastEncSym->Next)
{
ContextAt = MinContext = LastEncSym->Next;
}
else
{
ContextAt = allocContext(LastEncSym, ContextAt);
}
}
if (ContextAt)
{
while (--StackPtr != ContextStack)
{
ContextAt = allocContext(*StackPtr, ContextAt);
if (!ContextAt) break;
}
MaxContext = (*StackPtr)->Next = ContextAt;
}
if (!ContextAt) reset();
}
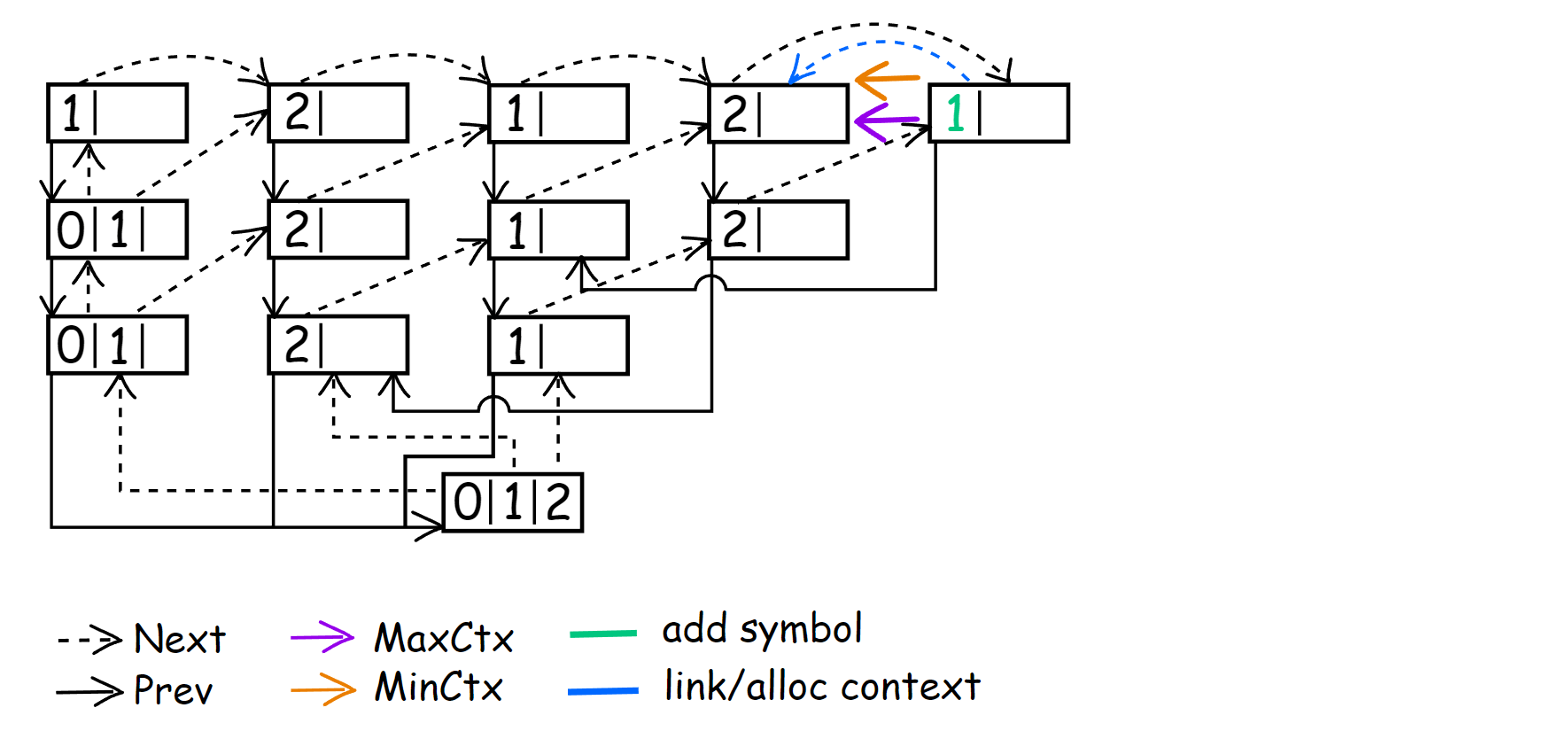
Instead of trying to describe what happens in this part of update(), let’s look at an example of context building. Below is a picture of the context tree after processing the first symbol [1]21212212.
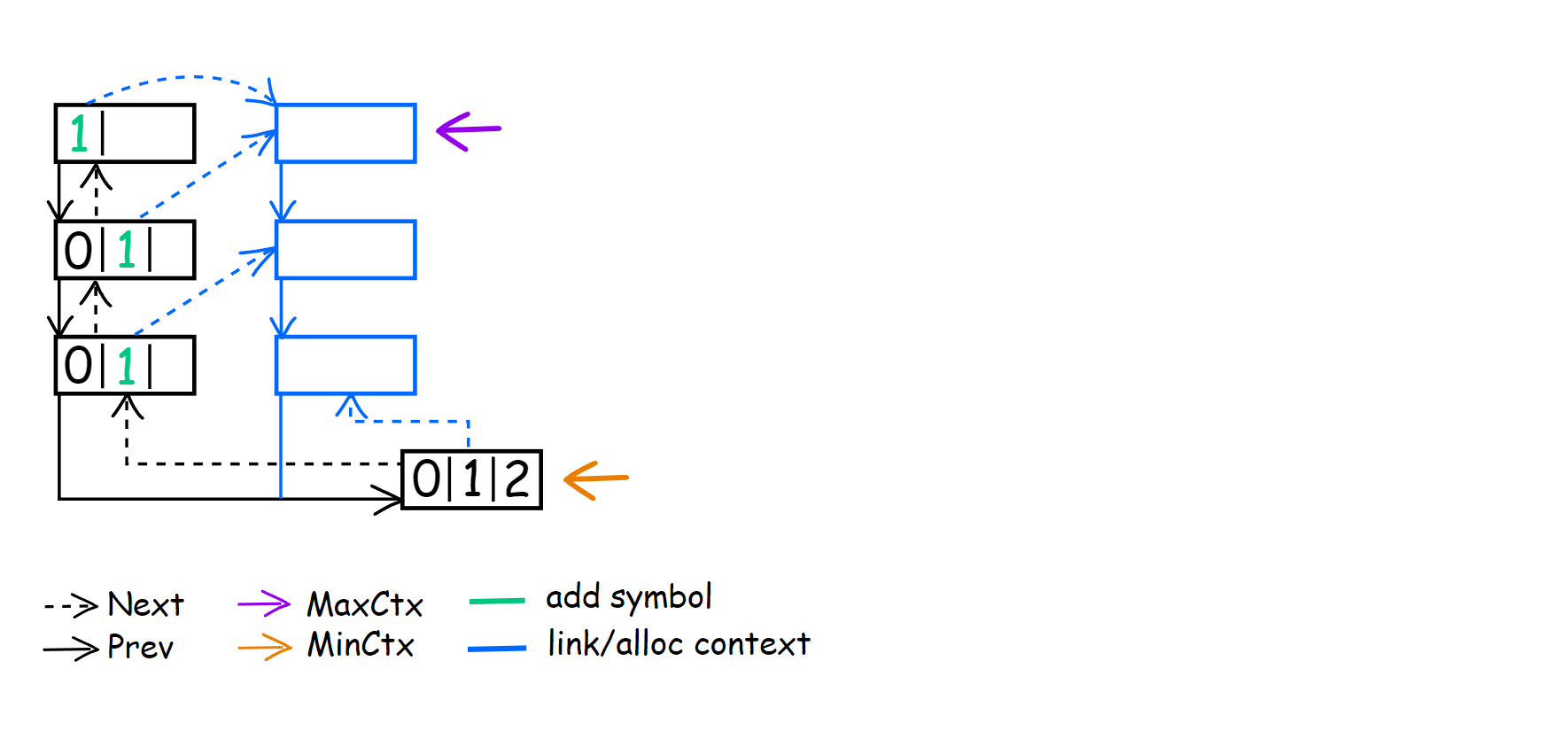
During the encoding of the first symbol ‘1’, descended to CM(0), which MinContext points to now. After all previous operations, ContextAt == MinContext. LastEncSym points to the symbol in CM(0) for which LastEncSym->Next was not set yet. Hence, the first things we do are perform the following:
1
ContextAt = allocContext(LastEncSym, ContextAt);
In this case, after this action, we link LastEncSym->Next with CM(1) <1> and at the same time set CM(0) as its child.
During the execution of while (--StackPtr != ContextStack), we continue building contexts and linking them between themselves. When we reach the first element of the ContextStack array, the condition will not be satisfied, and we break from the loop. As I understand it, this will always be the case for CM(N) context in order to have the ability to link them together.
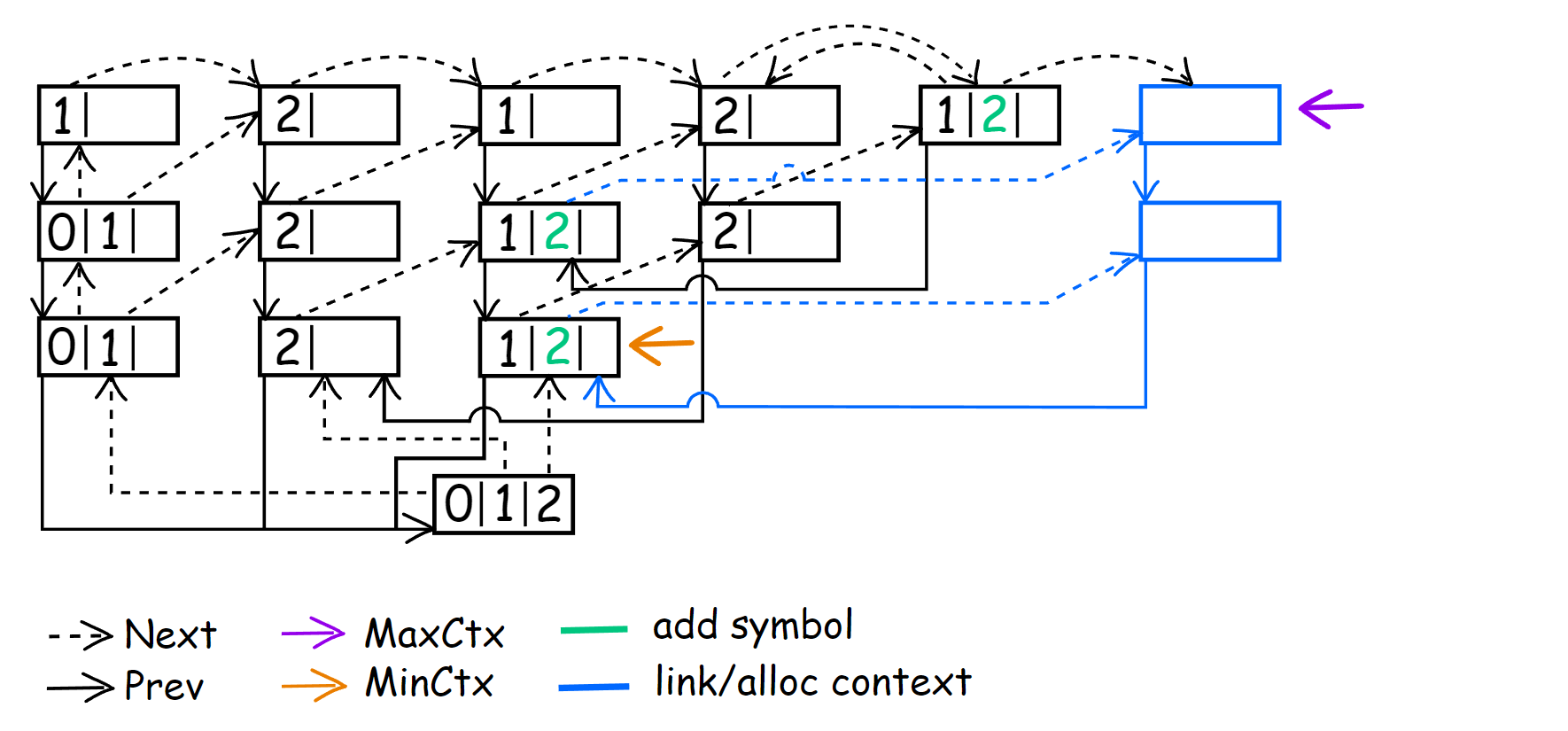
For the next symbol 1[2]1212212, we do everything by analogy. Only now LastEncSym points to the symbol ‘2’ in CM(0), so I skip this step and move on to show how the context tree will look like at the next symbol 12[1]212212.
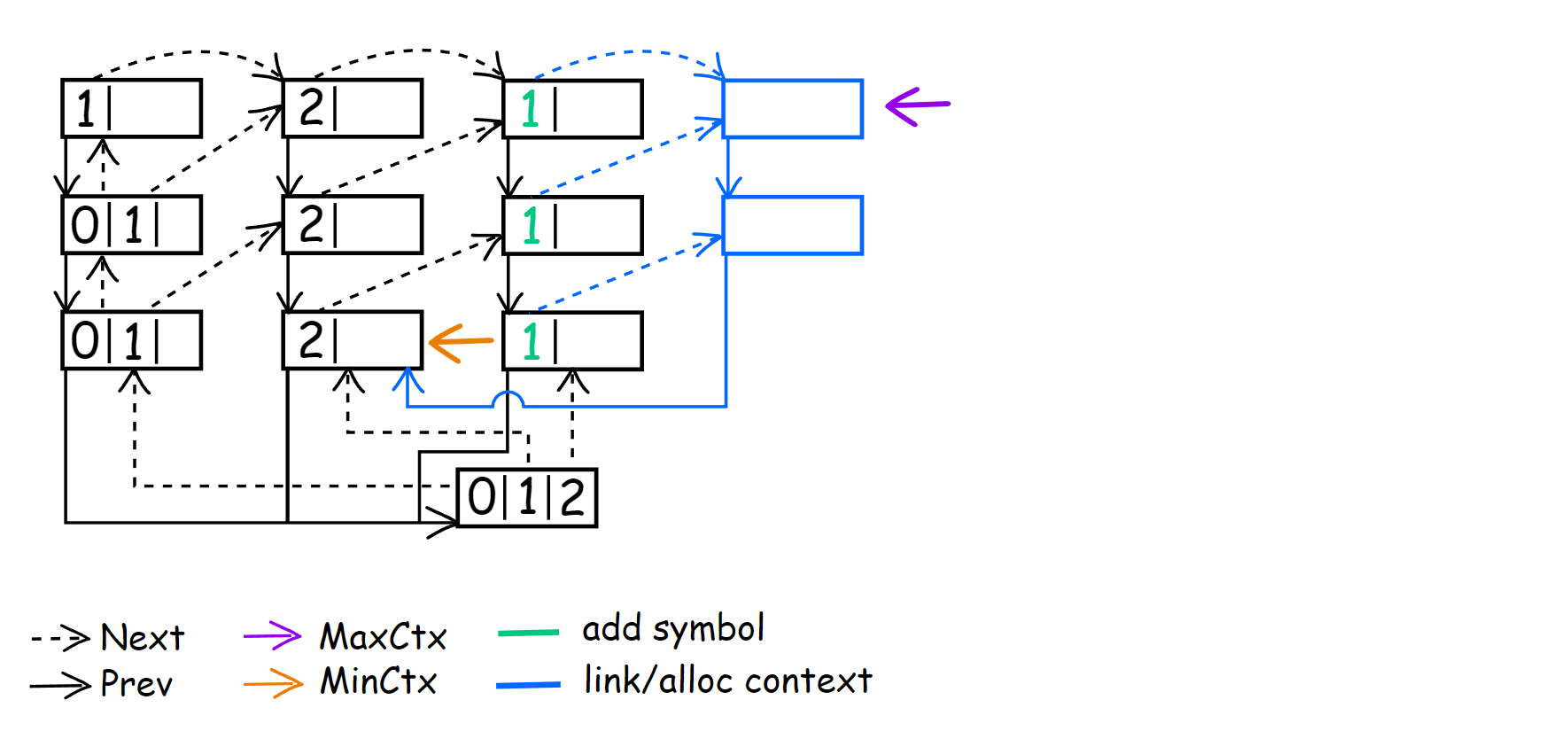
This time, after the symbol was encoded, we already had a parent context for LastEncSym, so we perform:
1
ContextAt = MinContext = LastEncSym->Next;
That’s why we don’t need to create CM(1) <1>. For the newly created CM(2) <21>, we set it as the child context. Now, we are at CM(1) <1> and our next symbol is 121[2]12212.
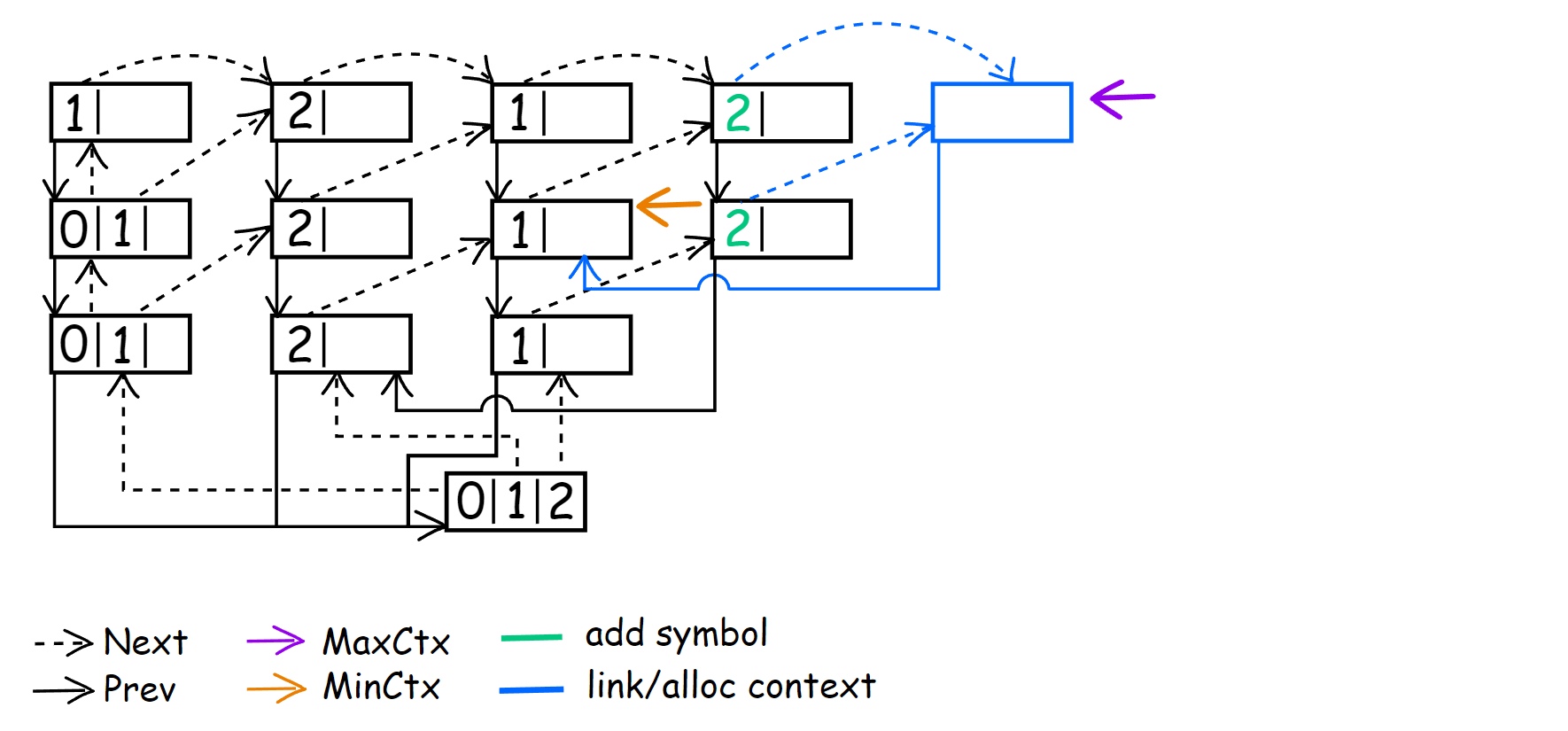
We’ve successfully encoded the symbol and moved to CM(2) <12>. As before, we link the context, so for the future CM(3) <212>, we set CM(2) <12> as a child. The next symbol is 1212[1]2212, and we again encode it successfully.
But this time, we initialize the symbol ‘1’ in CM(3) <212>. After that, we set MinContext to CM(3) <121> and link CM(3) <121> as the next to CM(3) <212>. This will be the first time when MinContext == MaxContext, so during the encoding of 12121[2]212, we simply perform:
1
2
3
4
if (MinContext == MaxContext)
{
MinContext = MaxContext = LastEncSym->Next;
}
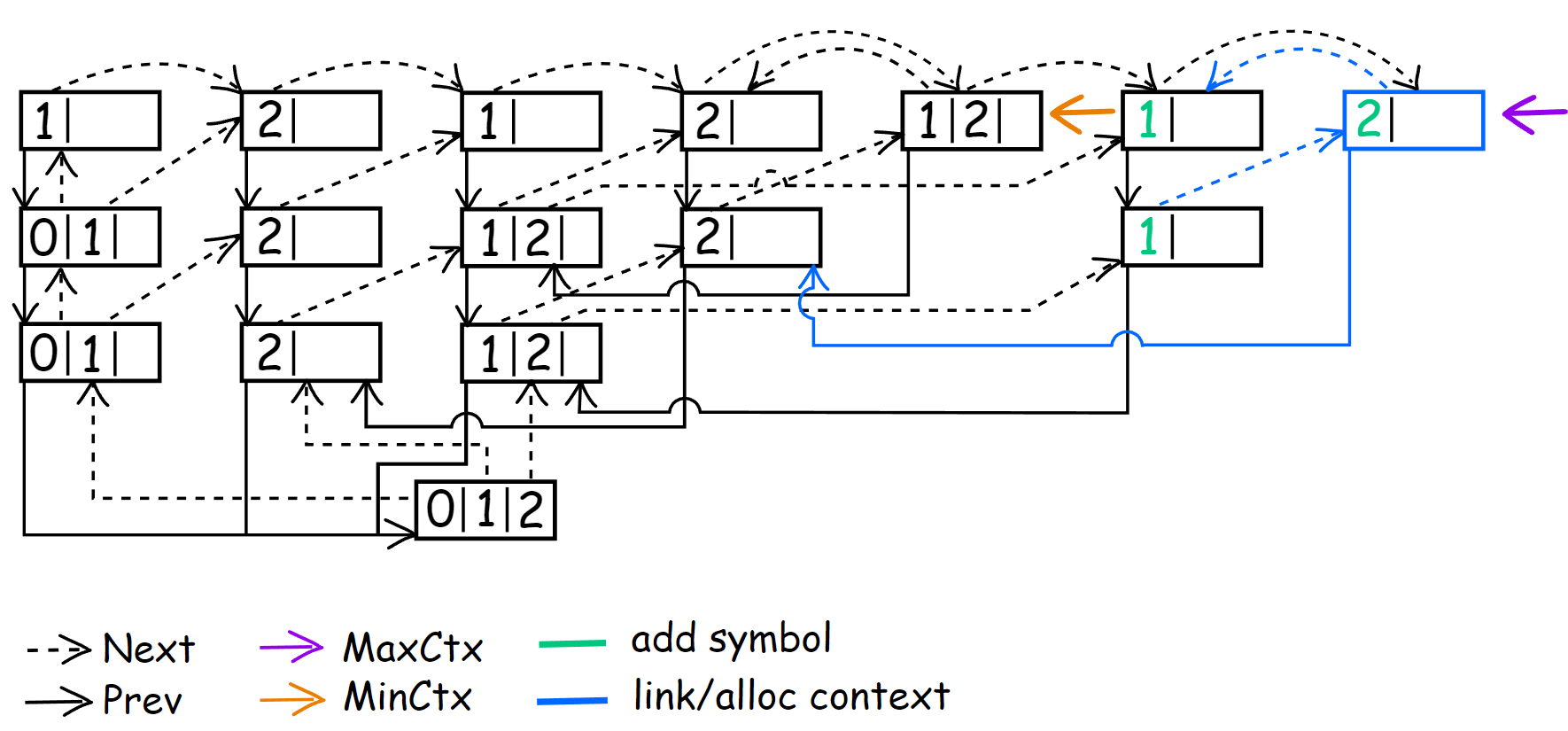
Skip update() and set MinContext and MaxContext to CM(3) <212>. During the encoding of 12121[2]212, we again have to go down to CM(0) because ‘2’ did not occur in any of these contexts: CM(3) <212>, CM(2) <12>, CM(1) <2>.
Because of this, we add ‘2’ to all of the listed contexts and immediately go to CM(1) <2>. Two new empty contexts have appeared: CM(2) <22> and CM(3) <122>. I have combined the result of encoding the last two symbols (1212122[1]2, 12121221[2]) into one image, as you probably grasp the general idea.
Result
Result of execution with the same parameter as last time (10 MiB and Order-4)
| name | H | file size | compr. size | bpb | Sym | ESC |
|---|---|---|---|---|---|---|
| book1 | 4.572 | 768771 | 223992 | 2.33 | 203217.1 | 20772.4 |
| geo | 5.646 | 102400 | 60955 | 4.762 | 51383.7 | 9569.5 |
| obj2 | 6.26 | 246814 | 77263 | 2.504 | 66282.3 | 10979 |
| pic | 1.21 | 513216 | 52641 | 0.82 | 45180.5 | 7411.3 |
| Intel.pdf | 7.955 | 26192768 | 25199413 | 7.697 | 22013555.8 | 3184528.6 |
The difference in execution speed in seconds.
| name | old enc | old dec | new enc | new dec |
|---|---|---|---|---|
| book1 | 0.174 | 0.186 | 0.092 | 0.1 |
| geo | 0.068 | 0.06 | 0.035 | 0.038 |
| obj2 | 0.087 | 0.087 | 0.032 | 0.032 |
| pic | 0.059 | 0.068 | 0.043 | 0.037 |
| Intel.pdf | 19.9 | 20.5 | 10.5 | 10.9 |
The changes in compression are minor, but the speed gain is nearly doubled. I remind you that we are currently using AC with 1 bit at a time normalization, so this is clearly not the best result that can be obtained.
The last thing I want to mention is the speed of contexts adapting to changes. Unlike the example in the image, we will actually have much more context. Now, we are still adding 1 to the symbol counter and calling rescale() on TotalFreq >= 16384. To speed up context adaptation, which in theory should give us a more accurate data model, we will increase the counter by 4 and call rescale() when any symbol exceeds the threshold that we set as 124. This also means that TotalFreq can have a value up to 31488 now. In order for our AC to correctly encode such edge cases, we need to change FREQ_BITS from 14 to 15.
1
static constexpr u32 FREQ_BITS = 15;
Changing the frequency update code for getEncodeProb() and getSymbolFormFreq().
1
2
3
4
5
6
7
MatchSymbol->Freq += 4;
MinContext->TotalFreq += 4;
if (MatchSymbol->Freq > MAX_FREQ)
{
rescale(MinContext);
}
| name | H | file size | compr. size | bpb | Sym | ESC |
|---|---|---|---|---|---|---|
| book1 | 4.572 | 768771 | 224287 | 2.33 | 194767.9 | 29517.3 |
| geo | 5.646 | 102400 | 62133 | 4.854 | 50653.8 | 11477.8 |
| obj2 | 6.26 | 246814 | 76934 | 2.494 | 62067 | 14866.1 |
| pic | 1.21 | 513216 | 91913 | 1.433 | 82483.1 | 9428.5 |
| Intel.pdf | 7.955 | 26192768 | 25913696 | 7.914 | 22067691.4 | 3844137.5 |
From one point of view, if we look at the Sym column, we can see that in some cases we really become spending fewer bytes for symbol encoding. But at the same time, ESC encoding becomes more expensive. Not to mention that the pic became almost 2 times larger! If we were to call rescale() at TotalFreq >= 16384, the result would not be better. At this stage, this change has not provided any benefits in terms of compression size. When using PPM, encoding ESC symbols becomes somewhat of an obstacle in achieving better compression. We will see what can be done with this in the next part.
Source code for this part.